人工智能和大模型的驱动下 数据中心GPU未来发展趋势
生成式人工智能和大模型的驱动下,我们正置身于一个算力领域千载难逢的拐点:一个类似于个人电脑、互联网、移动设备和云诞生的时刻。面对持续以10倍/年增长的大模型参数,一切传统上设计和构建算力基础设施的方式均已不再奏效,异构、Chiplet 及其引发的各种片内互联创新被推向台前。
作为一种已被多次证实有效尚富有生命力的技术,Chiplet 迅速激发了巨头们的斗志,并藉此武器,再次踏入一场数据中心算力形态的战争。
总体而言,在数据中心处理器领域,采用 Chiplet 化具有几大优势:
1、降低设计成本:
随着最新工艺制程的发展,芯片设计成本已增至令人望而却步的地步,根据 IBS 预估,2nm 芯片从头开发的总成本将达到 7.25 亿美元。使用 Chiplet 可以显著减少芯片研发时间和成本:只需对关键模块进行更新,就拥有了一个全新的芯片。从成本方面考虑,在不久的将来,随着制程的不断提升,如果不使用 Chiplet,几乎不可能构建领先的芯片。
2、降低量产成本:
总拥有成本(TCO)是在数据中心将模型投入生产的主要制约因素之一,而芯片的量产成本则是 TCO 的重要组成部分。当数据中心规模不断扩大,对 TCO 的影响也越大。根据 Tirias Research 预测,到 2028 年,一个典型 GenAI 数据中心服务器基础设施+运营成本将超过 760 亿美元。而 Chiplet 允许开发人员为每个模块选择不同工艺,灵活平衡性能与成本,而不必将所有功能都押宝在昂贵而难以获得的尖端制程上。
3、提升性能&集成度:
在摩尔定律和光照尺寸的限制下,Chiplet 已成为继续增强芯片性能经济而可持续的方式,通过 2.5D 平铺/ 3D 堆叠芯粒,可以有效扩展芯片性能,提升芯片的复杂度。当然,这也带来了互联的问题,毕竟,如果这些芯粒不能有效的连接在一起,就什么也做不了。
4、加速 TTM :
Chiplet 的另一项关键优势是可以缩短开发芯片的上市时间(TTM)。通过将复杂的功能隐藏在可重复使用的已验证芯粒中,企业可以有效缩短开发定制全新芯片所需的上市时间,并加速下一代产品的开发和创新。
本文将以英特尔和 Google 的代表性产品为例,分析数据中心 GPU 的发展趋势。
Intel - GPU Max
作为GPU 领域的新入局者,英特尔可谓野心勃勃,入场即从集成 GPU、中端独立 GPU 迅速杀至数据中心和超算市场。其首款面向服务中心的 GPU MAX(前代号 Ponte Vecchio)正是这样一款野心之作,基于 Intel Xe HPC 微架构,将超过1000亿个晶体管集成在47个芯粒里,堪称算力怪兽。

Source:Intel
量产成本下降
作为英特尔的首款服务中心 GPU,GPU MAX 的物理设计堪称 Chiplet 集大成者。通过将功能模块分离为 47 个芯粒,为每个不同芯粒单元分配 5 种不同制程。其中,Base tile 和 HBM2e SerDes 使用 Intel 7 工艺,计算单元采用 TSMC N5 工艺,从而实现成本的控制。
性能提升
GPU MAX 系列通过多达 47 颗芯粒的堆叠,提供 128 个 Xe-HPC 核心,408 MB 二级缓存和 64MB 一级缓存,以提高吞吐量和性能。英特尔表示,使用 Max 系列 GPU 的大型二级服务器,其 AI 工作负载的性能获得了 2 倍提升。
阿贡国家实验室是首批GPU Max系列采用者。其团队计划部署 60,000 个 Max 系列 GPU,平均分配给 10,000 个服务器刀片。每个刀片还依靠两个 Intel Xeon CPU Max 系列处理器来最大限度地提高 Aurora 的架构,以应对一些有史以来最重要的科学工作负载。一旦 ANL 在其旗舰 Aurora 系统上部署全套 Max 系列 GPU 和 CPU,双精度计算性能将超过 2 exaFLOPS。
47 颗芯粒,如何高速连在一起?
大型 GPU 上的 die 间传输数据并不容易,尤其对 GPU MAX 这样极度复杂的大型芯片来说,必须依靠高效的互连设计。

High level X e HPC Stack Component Overview, source: Intel
Base Tile(die):英特尔在 Max GPU 系列中引入了 Base Tile 的概念。Base Tile 是一种基础芯粒,与 interposer 的功能类似,用于承载计算核心和高速 I/O,但功能更加丰富。Max GPU 的 Base Tile 采用了英特尔 7nm 制程,将高速 I/O 的 SerDes 与计算核心解耦后重新打包在同一制程内,以降低量产成本。
此外,Base die 中还集成了一个容量为 144 MB的 RAMBO,以及 L3 Cache 的交换网络(Switch Fabric),通过 Switch Fabric 将144MB Cache 与 8 颗计算芯粒、4 颗 RAMBO 芯粒的 60MB Cache 连接在一起,最后通过3D Foveros 技术将计算芯粒堆叠在 Base die 之上,从而使得 GPU MAX 的互联效率大为增强,让芯粒间以最短的垂直路径互连为一个整体,从而极大的提升算力密度和更高的内存带宽。
Co-EMIB:EMIB + Foveros
为保障互联速度,每个 GPU MAX 被整合为两组镜像的 Chiplet 堆栈,堆栈间由 Co-EMIB 连接。Co-EMIB 是英特尔 2.5D EMIB 技术与3D 技术的 Foveros 结合产物,在堆栈间形成高密度互连的桥梁,互联密度可达 Base die 的两倍。
其中,EMIB 负责芯粒与芯粒之间的 2.5D 互连,而 Foveros 则在两个 3D 堆叠的芯粒堆栈间建立了密集的 die-to-die 垂直连接阵列,信号和电源通过硅通孔进入堆栈,较宽的垂直互连则直接穿透芯粒,形成距离更短的互联。
Chiplet 为英特尔这个 GPU 领域迟到的野心家按下了加速键,通过 Base die 和 2.5D、3D 互联技术的整合,为这款超级芯片注入惊人的性能和快速上市、快速迭代的基因,以实现与 AI 芯片霸主的正面竞争。
在今天,通过2.5D / 3D Chiplet 堆叠的形式扩展处理器的算力,已成为数据中心的主流路径。其中,Base die 作为3D Chiplet 的实现基础,已广泛应用于全球范围内的数据中心。随着 AIGC 应用的扩大化,通用化的 Base die 将迎来巨大的市场空间。国内市场通用 Base die 代表企业如奇异摩尔,旗下 Base die 将于年内流片。
Google TPU v5e
2023年8月,Goole Cloud 在 Next23 上,发布了其最新一代云端 AI 芯片 TPU v5e,TPUv5e 是 TPUv4i (TPUv4 lite) 的后继产品,一款专注于中大规模模型的训练和推理性能的精简版芯片。相比尚未发布的 TPUv5,TPU v5e 更加经济、高效,具有更小的尺寸和更低的功耗、内存带宽、FLOPS,功耗仅为 H100 的 20%。
降低成本
TPU 是一种特殊计算单元,可理解为针对张量计算的专用 GPU。与通用 GPU 相比,TPU 在特定任务方面的速度和能效方面表现更好。基于 Chiplet 架构的灵活性优势,Google 得以在 TPUv5 推出前,精简、优化架构,迅速推出这样一款极具成本效益的 TPU。
在面向 <200B 参数模型AI训练和推理时,TPUv5e 运行成本不到 TPU v4 一半(运行 TPU v4 的价格约为 3.2 美元/小时,TPU v5e 仅需 1.2 美元/小时),成本的大幅降低使组织能够以相同成本训练和部署更大、更复杂的 AI 模型。这对于许多第三方使用者来说,无疑具有巨大的成本优势。
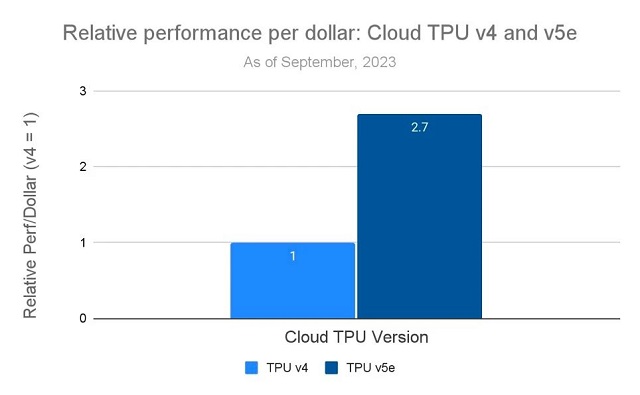
Throughput per dollar of Google’s Cloud TPU v5e compared to Cloud TPU v4. Souce:Google Cloud
根据版本大小不同,Google TPU会配备1个或2个 Tensor Core。相比未发布的全尺寸 TPU v5 芯片,TPUv5e 只保留了一个 Tensor Core和一半的 HBM 堆栈,大幅缩减了成本。不同于英伟达不惜牺牲功耗追求极致性能的策略,Google TPU 更好的利用了 Chiplet 的灵活性优势,快速推出多款面向不同客户需求的产品,并可以根据推出的精简版产品反馈灵活调整全尺寸芯片策略。
TPU v5e:更小而更强
尽管通过芯片减半降低实现了成本优化,TPU v5e 也实现了性能的大幅提升。Google 表示,TPU v5e 在各种人工智能负载实现高性能和高成本效益的推理,其性能较前代产品提高了 2-4 倍,成本效益提高超 2 倍。每个TPU v5e 芯片每秒可提供高达 393 万亿次int8 运算(TOPS),显著优于全尺寸的前代产品 TPU v4 的 275 petaflops,可对最复杂的模型进行快速预测。
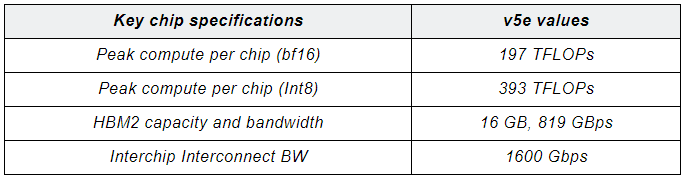
Tensor Core 同样基于 Chiplet 架构,每个 Tensor Core 由 4 个矩阵乘法单元 (MXU)、1 个向量单元和 1 个标量单元组成。通过对核心计算单元的优化,每个 MXU 每个周期可执行 16,000 次乘法累加运算。其中,6 个芯粒单元通过 2.5D interposer 进行单元间的高速互联,并与 HBM2E 内存进行通信,总内存带宽为 819.2GB/s。
TPUv4 & TPUv5e 架构对比
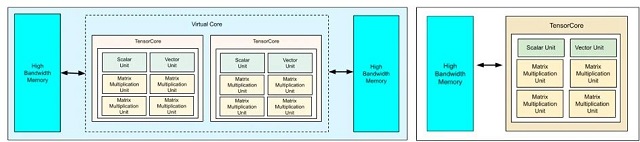
左为TPUv4,右为TPUv5e,Source:Google
2.5D interposer:
2.5D interposer即硅中介层,通常位于芯片底层 Substrate 和顶层芯粒间,通过硅通孔(Silicon Through Via, TSV)和 ubump 实现芯粒间的互连。2.5D Interposer 采用硅工艺,具有更小的线宽线距,ubump 尺寸更小,二者相结合,可以共同提升 IO 密度并降低传输延迟与功耗。
作为 Chiplet 架构的物理实现基础,2.5D interposer 已成为数据中心产品的普遍解决方案,可以让客户用更短的时间、更低的成本实现性能扩展。据 Yole 报告显示,2020年到 2025 年期间,2.5D interposer 的年复合增长率达 44%。
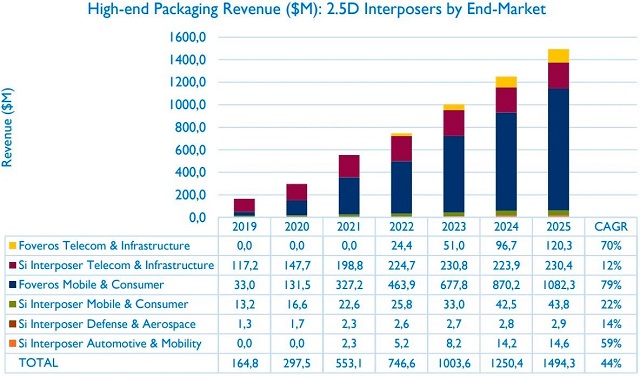
巨大的市场空间和加剧了竞争,2.5D interposer 的产能逐渐成为数据中心芯片供应的瓶颈,国内也应势产生了一系列2.5D interposer的厂商,奇异摩尔作为其中的代表,核心产品涵盖2.5D interposer、2.5D IO Die、3D Base Die等高性能互联芯粒、网络加速芯粒、全系列Die2Die IP及相关Chiplet系统解决方案,是目前国内少有的专注于Chiplet 互联赛道的企业。
高速发展的 AIGC 为世界带来了巨大的机遇与变革。同时,它也对我们所处的世界提出了更高的要求。在未来数年里,数据中心将会比现在强大上百倍,其训练和推理需要更强大的计算处理能力,更灵活、高效的架构,更低成本,更快的市场反应速度,这使得 Chiplet 及其互联技术在以 GPU 为代表的数据中心处理器架构中将成为必然。Chiplet 及其互联技术的统治地位才刚刚开始。
来源:(网络,侵删)
本文标题:人工智能和大模型的驱动下 数据中心GPU未来发展趋势
本文链接:https://www.blueocean-china.net/faq3/1018.html [版权声明]除非特别标注,否则均为本站原创文章,转载时请以链接形式注明文章出处。